Coding Now
初衷
一是平时看的一些自己认为不错的文章总是很难整理,所以打算开一个项目管理这些,也可以分享给大家;二是记录自己平时所学的一些笔记,一些经历,以供将来翻阅;三是想系统地进阶学习一番,记录这个项目也是想激励自己;四是分享一些平时看的电子书啊、视频等等
GitHub及Git使用
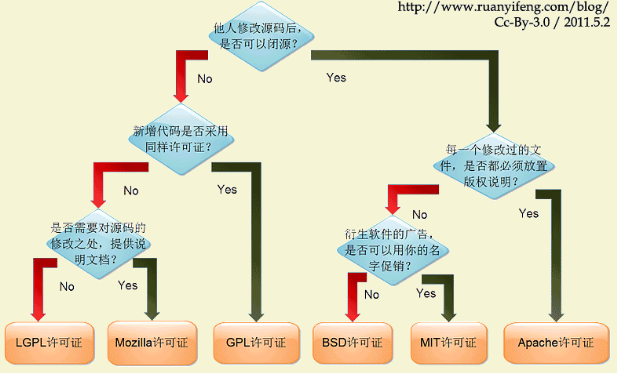
原文链接:https://paulmillr.com/posts/simple-description-of-popular-software-licenses/
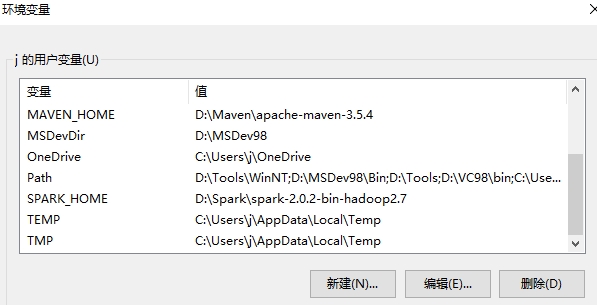
Linux系统下开发环境搭建
- Win10下安装双系统Deepin 15.8.md
- Deepin15.8下搭建Python开发环境.md
- Deepin下搭建Hadoop、Spark等大数据开发环境.md
- Deepin下如何科-学(地)上-网.md%E4%B8%8A-%E7%BD%91.md)
- Deepin常用快捷键及其他便利操作.md
Linux命令及Shell脚本学习笔记
爬虫篇(Python)
爬虫这一块我也没多少可以说的,距离我上次写爬虫程序都有一年多了。谈谈感想吧,别听什么培训机构诳你什么爬虫工程师有前途啥的,当然学好学精爬虫也能拿到高薪,但这一行也有不少人了,精通的自然不用说。而且现在有很多像八爪鱼、火车头这些可以定制的爬虫软件,还有一些自学习的爬虫框架。所以我觉得爬虫这一块只要稍微学下,了解下即可
我建议如果是python的话,了解urllib(http请求),requests(http请求),lxml(文本解析),Scrapy(爬虫框架),多线程爬虫就可以了
原来也在csdn上写过一些scrapy的文章,当然学习一门语言官方文档才是最重要的(scrapy也有中文的)
- Scrapy入门学习初步总览
- 解决Windows下pip install scrapy 出错 及 pycharm使用安利
- scrapy入门学习初步探索之数据保存
- 爬取通过ajax动态加载的页面(实时监控华尔街见闻资讯与快讯)
- Python爬虫:人人影视追剧脚本
- 爬取大西洋月刊每日新闻
- (补充)爬取大西洋月刊并 使用彩云小译翻译 API 脚本
数据分析篇
机器学习及深度学习篇
机器学习网站及教程
- 机器学习入门教程与实例-SofaSofa
- scikit-learn: Python 中的机器学习 — scikit-learn 0.19.0 中文文档 - ApacheCN
- 问题构建 (Framing):机器学习主要术语 | 机器学习速成课程 | Google Developers
- 机器学习实战-ApacheCN-github
- MachineLearning100/100-Days-Of-ML-Code: 100-Days-Of-ML-Code中文版
- 机器学习、图像声音处理文章列表 - TinyMind
- 机器学习-Label Encoding与One Hot的区别-20180513
- 机器学习与深度学习 - 连载 - 简书
- 【干货】史上最全的Tensorflow学习资源汇总
- GitHub - apachecn/hands_on_Ml_with_Sklearn_and_TF: OReilly Hands On Machine Learning with Scikit Learn and TensorFlow (Sklearn与TensorFlow机器学习实用指南)
- AI研习社 - 研习AI产学研新知,助力AI学术开发者成长。
GitHub上相关项目推荐
- homemade-machine-learning (在家学习机器学习),现在6.9K星,确实不错,不过全英文的
数据分析竞赛
哪里可以参加比赛?【我常去的就这几个】
- 进行中百度点石
- 竞赛信息-DC竞赛
- 大数据挑战赛 - Kesci.com
- Kaggle: Your Home for Data Science
- 还有阿里天池大赛,但参加了几次,我还是段位不够啊,太难了
赛事代码学习资源
- 竞赛相关系列文章
- 机器学习中特征工程,如何进行数据分析嘞? - 知乎
- 几个相关系数:Pearson、Spearman、pointbiserialr、kendalltau - 程序园
- Kaggle: 房价预测 - 代码天地
- 如何在 Kaggle 首战中进入前 10% | Wille
- python进行机器学习(一)之数据预处理 - 光彩照人 - 博客园
- 随机森林sklearn FandomForest,及其调参 - 码灵薯的博客 - CSDN博客
- 【集成学习】scikit-learn随机森林调参小结 - sun_shengyun的专栏 - CSDN博客
- 加州房价预测数据预处理 - 多一点 - 博客园
- 加州房价预测项目精细解释 - CSDN博客
- 机器学习:数据预处理之独热编码(One-Hot)_慕课手记
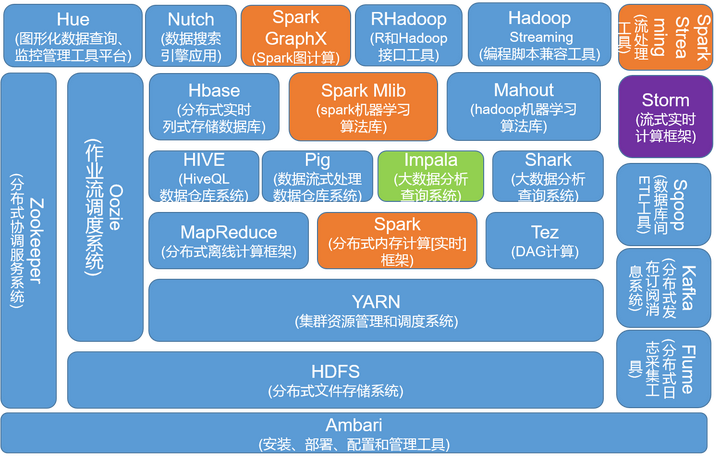
大数据篇
大数据开发环境安装配置
以下出自我在csdn上的一些文章,https://blog.csdn.net/lzw2016/
Hadoop系列
Apache Hadoop: 是Apache开源组织的一个分布式计算开源框架,提供了一个分布式文件系统子项目(HDFS)和支持MapReduce分布式计算的软件架构
掌握MapReduce编程
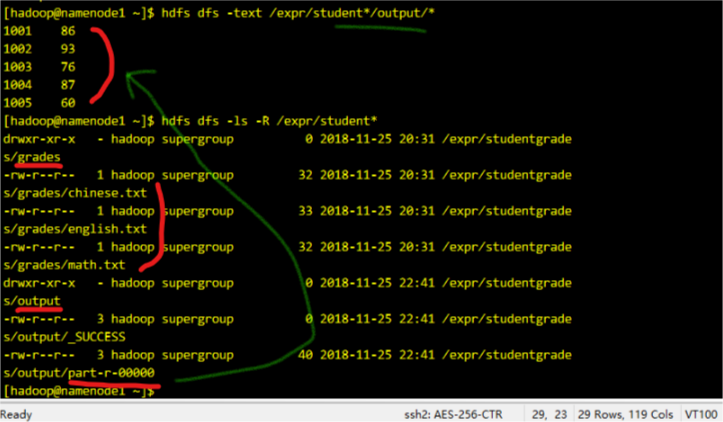
- 01MapReduce编程初步及源码分析.md
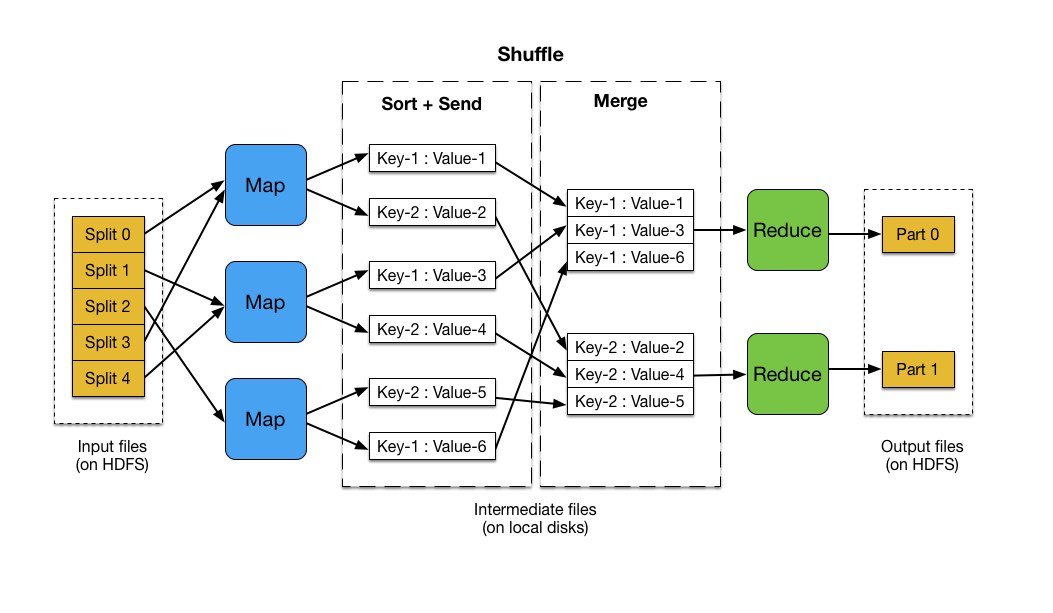
- 02【MapReduce详解及源码解析(一)】——分片输入、Mapper及Map端Shuffle过程
- 03 MapReduce-Demo——这是我另外一个项目,从多个设计模式实战 MapReduce 编程实例
仅供参考:


推荐几个博客分类博主LanceToBigData:Hadoop ,小小默’s Blog,分类很乱但是内容确实不错
Apache Hive: 是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析
Apache Pig: 是一个基于Hadoop的大规模数据分析工具,它提供的SQL-LIKE语言叫Pig Latin,该语言的编译器会把类SQL的数据分析请求转换为一系列经过优化处理的MapReduce运算 【不准备学,计划Hive代替Pig】
Apache HBase: 是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群
Apache Sqoop: 是一个用来将Hadoop和关系型数据库中的数据相互转移的工具,可以将一个关系型数据库(MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中
Apache Mahout:是基于Hadoop的机器学习和数据挖掘的一个分布式框架。【不打算学,计划利用SparkMLLib代替】
Apache Zookeeper: 是一个为分布式应用所设计的分布的、开源的协调服务,它主要是用来解决分布式应用中经常遇到的一些数据管理问题,简化分布式应用协调及其管理的难度,提供高性能的分布式服务
Apache Flume: 是一个分布的、可靠的、高可用的海量日志聚合的系统,可用于日志数据收集,日志数据处理,日志数据传输
等等,当然不可能全学的
面试篇
Spark系列
实战项目
推荐系统
- 【推荐系统入门】推荐系统理论初探 及 豆瓣推荐应用举例分析
itemcf——ItemCF算法的MapReduce实现代码
待续
算法篇
网课
-
算法课程Coursera网上主推的是Robert Sedgewick的算法课【红宝书的作者,普林斯顿计算机系创始人】
- 还有一门是Coursera上的斯坦福大学的算法课,我感觉偏理论,难度不如上面的那门
-
推荐一门面试课,我感觉还是可以的,极客时间的【数据结构与算法之美】
在线刷题:LeetCode练手
LeetCode现在有中文版的了,力扣中国
每周基于Java、C++的LeetCode刷题记录
- 文档记录:LeetCode刷题心得.md
- 代码驱动:【待补充】
GitHub项目推荐
eBook和视频资源
只推荐我看过的,且个人觉得不错的
Python
视频资源 点这里—>eBook/Python
- Python3数据分析与挖掘(某课网)
- python分布式爬虫打造搜索引擎【完整版 某课网】
- Python升级3.6 强力Django+Xadmin打造在线教育平台
电子书推荐,下面给了几个可以下载电子书的网站,都能找得到的
- 入门
- 《Python基本教程》,貌似出第三版了
- 《Python核心编程》
- 《Python CookBook》
- 爬虫
- 《Python网络数据采集》
- 也有人推荐崔庆才的书,我只看过他的博客觉得挺不错的,书想比也可以吧
- 我更推荐看博客,爬虫这一块更新太快了,书跟不上步伐
- 数据分析
- 《用Python进行数据分析》足以
- 机器学习和深度学习
Hadoop系列
Spark系列
视频资源 点这里—>eBook/Spark系列
Spark 2.0从入门到精通245讲 【墙推】
01-基于Spark2.x新闻网大数据实时分析可视化系统项目
- 02-Spark离线和实时电影推荐系统直播回放(视频+文档+代码)
- 03-Spark项目实战:爱奇艺用户行为实时分析系统
- 04-Spark企业级实战项目:道路交通实时流量监控预测系统
- 05-Spark企业级实战项目:知名手机厂商用户行为实时分析系统
- 06-Spark大型项目实战:电商用户行为分析大数据平台
以上来源于大数据学习资源群的分享
算法系列
数据库
计算机网络
基础书籍
常用网站收纳
Stack Overflow搜索栏,程序猿都该去的网站(当然还有GayHub)
Coursera,没事可以听听网课
All IT eBooks - Free IT eBooks Download——电子书下载【English】
Java各大开发者网站
Python各大开发者网站
工具
搜索
- Bird.so 小众搜索引擎
- Google 镜像站
- GF导航_想你所想——网址收纳导航
翻译
文档编辑
- Online LaTeX Equation Editor ——在线 LaTeX 编辑器
- PDF在线转换工具
制图、图床
插件
- Chrome Extension Downloader——可以通过此网站来下载因为某些原因无法在线安装 Chrome 插件

 针
针