基本语法
DDL
- 建表:
create table table_name(XXX)- 使用旧表创建新表
create table new_table like old_tablecreate table tab_new as select col1,col2… from tab_old definition only
- 删表:
drop table table_name - 创建视图:
create view view_name as select语句 - 删除视图:
drop view view_name - 更新表:
Alter table table_name XXX
DML
注意点
完整性约束:实体(主键)/参照(外键)/用户自定义完整性约束
- 基于元组、属性的check约束:涉及元组的多个属性的约束,要用基于元组的约束
与基于属性的CHECK约束相比,基于元组的CHECK约束检查的更频繁,只要该元组的任一个属性被改变,都要检查。而基于属性的CHECK约束只有在相应的属性变化时才检查。
- 基于元组、属性的check约束:涉及元组的多个属性的约束,要用基于元组的约束
sql server 中的isnull(),和MySQL中的ifnull()是否一样
- MySQL中avg()可以传入两个参数
截取/保留小数点后n位
- round(num,n) 保留数num小数点后n位,会自动四舍五入
- truncate(num,n),同上但不四舍五入
- 以上n为负数的话,会截取整数部位
- format(num,n),只能截取小数点后(含0),会四舍五入
1
2
3
4
5
6
7
8
9
10
11
12
13
14SELECT ROUND(123.1235,3);
# 123.124
SELECT TRUNCATE(123.1235,3);
# 123.123
SELECT ROUND(123.1235,-1)
# 120
SELECT ROUND(123.1235,0)
# 123
SELECT format(123.1235,3)
# 123.124
mysql不支持full join(全连接),但可以使用合并(union)左连接(left joing)和右连接(right join)
- 如何不通过max()、排序查询最大值?
使用集合差集,先查出除最大值之外的所有值,再用全体相减即可
如查出emp表中工资最大值
1 | SELECT sal |
查找前6到10条记录
- SQL Server支持top n输出前n条记录
- MySQL无top用法,但是有limit M,N(从M+1开始输出N条记录)
1
2
3
4
5-- sql server
select top 10 * from users
where userID not in(select top 5 userID from users)
-- mysql
select * from users limit 5,5
按照id排序后,输出前6到10条记录
- 按照上面提到的,另加一步排序操作
- 使用Row_number()名次函数,删选6到10
1
2
3
4-- sql server
select *,Row_number() over(order by id) rank
from users
where rank between 6 and 10;
区分Row_number()、Rank()、Dense_Rank()、ntile()名次的区别:【sql】— SQL Server 中的排名函数
- 4个函数的用法都是
XXX() over(order by xx )(必须有含order by的over子句) - over中的order by语句和select语句中是否排序无关联
- 分组内从1开始排名次
参考:Sql 四大排名函数(ROW_NUMBER、RANK、DENSE_RANK、NTILE)简介
- Row_Number():为每一行都会生成一个名次序号,依次排序不重复
Rank():为over子句中排序字段相同的生成一样的序号,下一个序号是前面的记录数+1(跳跃排序)
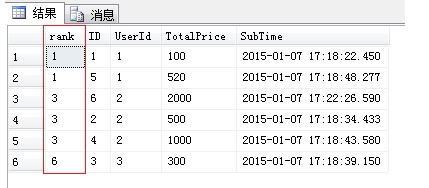
Dense_Rank():类似Rank,但属于连续排序,下一个序号是承接上一个序号的
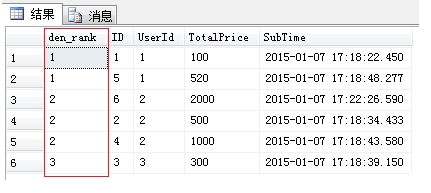
- NTILE(n):有一个参数n,指定分为多少组
- 每组含多少记录数有一个策略
- 每组的记录数不能大于它上一组的记录数,即编号小的桶放的记录数不能小于编号大的桶。也就是说,第1组中的记录数只能大于等于第2组及以后各组中的记录数。
- 所有组中的记录数要么都相同,要么从某一个记录较少的组(命名为X)开始后面所有组的记录数都与该组(X组)的记录数相同。也就是说,如果有个组,前三组的记录数都是9,而第四组的记录数是8,那么第五组和第六组的记录数也必须是8。
- 每组含多少记录数有一个策略
首先系统会去检查能不能对所有满足条件的记录进行平均分组,若能则直接平均分配就完成分组了;若不能,则会先分出一个组,这个组分多少条记录呢?就是 (总记录数/总组数)+1 条,之所以分配 (总记录数/总组数)+1 条是因为当不能进行平均分组时,总记录数%总组数肯定是有余的,又因为分组约定1,所以先分出去的组需要+1条。
分完之后系统会继续去比较余下的记录数和未分配的组数能不能进行平均分配,若能,则平均分配余下的记录;若不能,则再分出去一组,这个组的记录数也是(总记录数/总组数)+1条。
然后系统继续去比较余下的记录数和未分配的组数能不能进行平均分配,若能,则平均分配余下的记录;若还是不能,则再分配出去一组,继续比较余下的……这样一直进行下去,直至分组完成。
MySQL中如何实现Rank名次函数
1 | -- mysql实现名次函数 |
> 要在mysql中声明一个变量,你必须在变量名之前使用@符号。FROM子句中的(@curRank := 0)部分允许我们进行变量初始化,而不需要单独的SET命令。当然,也可以使用SET,但它会处理两个查询:
1
2
3
4
SET @curRank := 0;
SELECT *, @curRank := @curRank + 1 AS rank
FROM players
ORDER BY id
- 局部常量@(用户定义) 和全局常量@@(系统定义,只读)
- MySQL在使用时单一set、select局部常量时可以直接
set @p = 1,但要是涉及该变量赋值要用set @p := 1,select @p := @p+1文档在这
数据库考试知识点
- 数据库系统的核心和基础(数据模型)
- 保证数据库系统中的数据具有较高逻辑独立性的是(视图层/逻辑层映像)
- 将现实世界抽象为信息世界的是(概念模型)
表和视图
- 表是内模式,视图是外模式
- 表只用物理空间而视图不占用物理空间,视图只是逻辑概念的存在,表可以及时对它进行修改,但视图只能有创建的语句来修改
- 表属于全局模式中的表,是实表;视图属于局部模式的表,是虚表
- 视图的建立和删除只影响视图本身,不影响对应的基本表
- 基本表和视图都是关系,视图是基本表的抽象和在逻辑意义上建立的新关系
- 视图之上还能定义视图
SQL语言(结构化查询语言),数据查询、定义、操纵、控制
高度非过程化,采用面向集合的操作方式
(非关系数据模型是过程化的,采用面向记录的操作方式)
- unique约束可以插入NULL,多个NULL也不算重复(因为和NULL比较结果unknown,所以多个NULL值存在不违反唯一约束)。但 Oracle中 复合属性的唯一约束不同
Oracle唯一约束中NULL处理
1 | CREATE TABLE test1(id NUMBER, id2 NUMBER); |
NOT EXISTS... [EXCEPT]...模板
1 | Product (pID, name, category, UnitType, sID, price ) |
not exists就是【没有、从未】,其后跟随的子查询就是要解决的后半段问题【肯定部分】
1 | Select pID, name |
数据库设计
- 候选码K:若K(属性或属性集合)可以完全函数依赖确定全部属性U,则K就是候选码
- 主属性:候选码的子集
- 1NF:【最基本的】 关系模式R的所有属性 域都是原子的(不可分的)
- 2NF:不存在非主属性对候选码部分函数依赖(也就是说非主属性完全函数依赖于候选码)
- 3NF:不存在非主属性对候选码传递依赖(第三范式又可描述为:表中不存在可以确定其他非主属性的非主属性)
- BCNF:只要属性或属性组A能够决定任何一个属性B,则A的子集中必须有候选键(F的左侧包含超码)
求F+
- 第一步:设最终将成为闭包的属性集是Y,把Y初始化为X;
- 第二步:检查F中的每一个函数依赖A→B,如果属性集A中所有属性均在Y中,而B中有的属性不在Y中,则将其加入到Y中;
- 第三步:重复第二步,直到没有属性可以添加到属性集Y中为止。 最后得到的Y就是X+
X是题目会给出的,求谁(X)的闭包;Y是最后所求得的闭包
设关系R(A,B,C,D,E,G)有函数依赖集
F={AB→C,BC→AD,D→E,CG→B},求AB的闭包
X = {A、B} {A、B}+ = Y={A、B、C、D、E}
由上可知,F逻辑蕴涵AB->D (因为D被{A、B}+包含)
求候选码
候选码:能唯一标识元组的属性组;候选码的闭包是全集U,没有冗杂
对应R< U、F>(U是属性集,F是函数依赖集)
- 如果有属性不在F中出现,那么它必须包含在候选码中
- 如果有属性在所有函数依赖中一直存在于左边,则它必包含在候选码中;同理只在右边出现过的属性一定不属于候选码
- 如果有属性或属性组能唯一标识元组,则它就是候选
先用前两条,都不满足就凭借最后一条一个一个找
有时候选码不止一个,都细分一下
判断满足的最强范式(BCNF、3NF、1NF,感觉2NF都不是)
通过定义
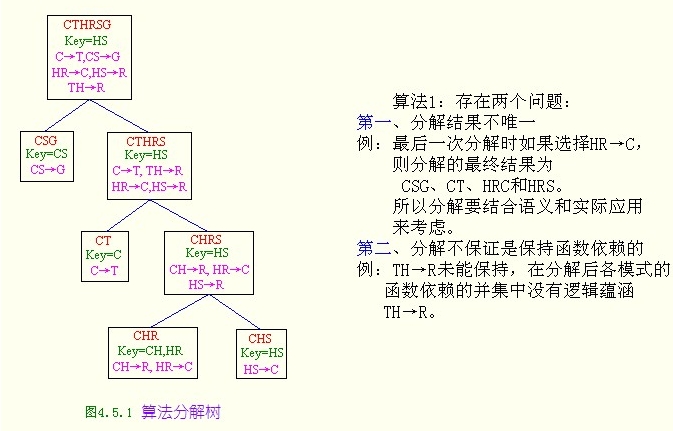
不满足BCNF的关系模式分解为BCNF
对于R<U、F>
- 初始化
result={R} - 找到R中的一个模式S不属于BCNF,且F+中存在一个X->Y(Y不包含于X),X也不是S的候选码,则S就能分解为
{S1、S2}。S1=XY,S2=(S-A)X,用{S1、S2}代替result中的{S} - 继续执行上面这步直到result中所有关系模式都是BCNF
例:关系模式
R<U,F>,其中U={C,T,H,R,S,G},F={CS→G,C→T,TH→R,HR→C,HS→R},将其分解成BCNF并保持无损连接。
例:关系模式R<U,F>,其中:
U={A,B,C,D,E},F={A→C,C→D,B→C,DE→C,CE→A},将其分解成BCNF并保持无损连接。
2
>

