前言准备
Win10上通过VMware12 + Centos7准备好了基本环境,配置虚拟机的子网IP地址(我这里是192.168.17.0),如图通过管理员可配置子网IP,掩码,网关(我这里是192.168.17.2)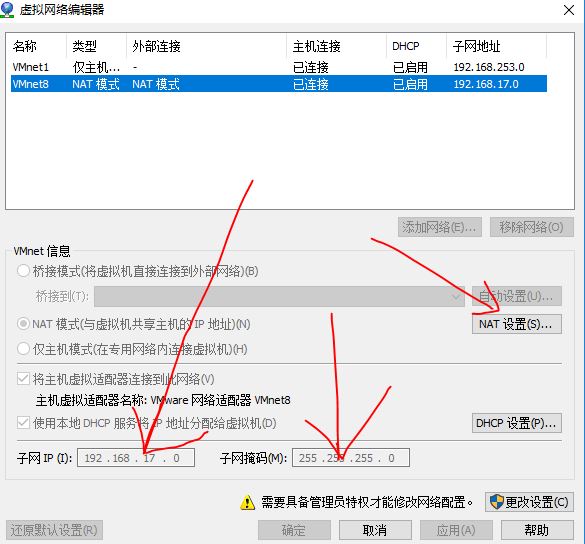
伪分布式特点
具备Hadoop的所有功能,在单机上模拟一个分布式的环境,需要配置hdfs和yarn框架
- HDFS:主节点:master,从节点:slave 【伪分布式这里也是master】
Yarn:容器,运行MapReduce程序
下载安装
这里下载Linux版本:http://www.oracle.com/technetwork/java/javase/downloads/index.html ,我这里使用的是 jdk-8u131-linux-x64 版本
首先要把下载的文件上传到centos系统下的随便那个目录下(最好root下),把文件解压缩到/root 目录下
以下操作都是在root管理员权限下操作
1 | cd /root |
- 环境配置
编辑环境变量,在/etc/profile文件中添加如下变量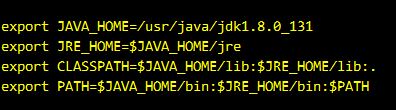
注意,我这里jdk1.8.0_131换成你下载的jdk版本号即可
- 测试
命令行下输入 java -version,能正确查看到java的版本就表示上面步骤配置成功
配置虚拟机网络环境
首先要知道完全分布式和伪分布式的原理是一样的,都得有master和slave节点,节点之间通信时不可能有DHCP临时随机配置IP,所以要配置虚拟机的固定IP
- 设置静态IP
同样是在/etc下(这是配置文件所在地)1
2
3
4
5ls sysconfig/network-scripts/ifcfg-ens*
# 输出结果就是要配置的文件
vi sysconfig/network-scripts/ifcfg-en*
# 进入编辑
改动以下设置1
2
3
4
5
6BOOTPROTO=static //改成static
ONBOOT=yes //改成yes
IPADDR=192.168.17.10 //随便设,不过要在子网192.168.17.0下
NETMASK=255.255.255.0 //掩码
GATEWAY=192.168.17.2 //第一步配置时设好的
DNS1=192.168.17.2 //随便写
- 设置主机名
命令行下输入hostname可查看主机名,一般是localhost,但为了方便重新设置主机名1
vi /etc/hostname
删掉原先的,配置主机名(如master,namenode等)
- 绑定IP地址和主机名
1 | vi /etc/hosts |
- 关闭防火墙
我这里是centos,防火墙是firewall,而不是iptables【其他系统有其他关闭方法】。防火墙务必要关闭,否则完全分布式搭建的话无法和其他主机相连
1 | systemctl stop firewalld //停止firewall服务 |
然后可以通过systemctl status firewalld查看防火墙状态1
Active: inactive (dead) //这就是关闭了
- 重启网络服务
systemctl restart network,然后你可以ping以下主机名ping master,看可以ping通吗,可以的话就OK
配置Hadoop的环境
下载Hadoop
(1) apache hadoop:http://www-us.apache.org/dist/hadoop/common/ 【这个是开源的】
(2) cloudera hadoop(CDH):http://archive-primary.cloudera.com/cdh5/cdh/5/ 【推荐使用】
CDH是hadoop的一个版本,我们老师推荐的,原因没记住是啥
上传并解压安装
我这里是下的hadoop-2.6.0-cdh5.12.1,一样是上传放在了/root目录下1
2
3tar -zxvf hadoop-2.6.0-cdh5.12.1.tar.gz -C /home/hadoop //把hadoop-2.6.0-cdh5.12.1解压到/home/hadoop目录下
cd /home/hadoop/hadoop-2.6.0-cdh5.12.1 //切换到该目录下
hdfs在运行时需要name,data,logs,tmp文件夹用来存放原数据,实际数据,日志,临时文件1
mkdir hdfs hdfs/name hdfs/data logs tmp //在hadoop目录中创建
配置Hadoop环境变量
1 | vi /home/hadoop/.bash_profile |
中文去掉
修改hadoop配置文件
我在文末会放一个链接,你可以直接下载,修改其中的主机名上传到/home/hadoop/hadoop-2.6.0-cdh5.12.1/etc/hadoop目录下,覆盖原文件即可
cd /home/hadoop/hadoop-2.6.0-cdh5.12.1/etc/hadoop
中文统统都去掉
- 设置java所在环境变量
在hadoop-env.sh、mapred-env.sh、yarn-env.sh中分别设置JAVA_HOME
1 | export JAVA_HOME=/usr/java/jdk1.8.0_131 //之前设置的 |
- 配置slaves文件 设置slave节点名
1
2
3
4vi slaves
#添加slave节点名
master
因为是伪分布式,一台虚拟机充当master也充当slave
- 修改log4j.properties文件
追加一行内容:log4j.logger.org.apache.hadoop.util.NativeCodeLoader=ERROR,避免启动时报警
配置core-site.xml
1
2
3
4
5
6
7
8
9
10<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value> //指定对外访问接口
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoop-2.6.0-cdh5.12.1/tmp</value> //指定临时文件放哪
</property>
</configuration>配置hdfs-site.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/hadoop-2.6.0-cdh5.12.1/hdfs/name</value> //元数据放哪
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/hadoop-2.6.0-cdh5.12.1/hdfs/data</value> //实际数据放哪
</property>
<property>
<name>dfs.replication</name>
<value>1</value> // 这个1是指定数据备份几份 【默认3份,伪分布式1是因为只有一个slave】
</property>
<property>
<name>dfs.permissions</name>
<value>false</value> // 跳过身份验证
</property>
</configuration>
以上是hdfs的配置,下面是yarn的配置
- 配置mapred-site.xml文件
cp mapred-site.xml.template mapred-site.xml
该文件默认不存在,需要用模板文件来创建
1 | <configuration> |
配置yarn-site.xml文件
1
2
3
4
5
6
7
8
9
10<configuration>
<property>
<name>yarn.resourcemanager.hostname</name> //配置ResourceManager的地址
<value>master:8031</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name> //配置NodeManager执行任务的方式
<value>mapreduce_shuffle</value>
</property>
</configuration>设置hadoop目录的owner
1
chown -R hadoop:hadoop /home/hadoop/hadoop-2.6.0-cdh5.12.1 //修改hadoop目录的owner
以上就是Hadoop基本配置
配置hadoop用户免密登录
从上文可以看出,我的centos的普通用户是hadoop(/home/hadoop),设置hadoop用户免密登录可以便于集群间后台数据传输时省去密码的输入过程
这里使用ssh免密登录,rsa加密算法
- 切换到hadoop用户
- 命令行执行
ssh -keygen -t rsa- 遇到提示时,回车即可;三次回车
- 默认会在
/home/hadoop/.ssh/下生成私钥(id_rsa)、公钥(id_rsa.pub)
进入.ssh目录,把公钥汇总到授权文件(authorized_keys),并授权1
2
3cd ~/.ssh
cat id_rsa.pub >> authorized_keys //在master执行,合并授权文件
chmod 600 authorized_keys //设置授权文件的访问权限为读写
如果是完全分布式搭建,这里略有不同。要在每台主机上都生成公钥、私钥,并把公钥汇总到master节点的授权文件中,然后master再把授权文件分发给每个节点
- 测试ssh免密登录
如果配置成功,输入ssh master[主机名]即可登录,登录会显示Last login:XXX...。第一次登录会有提示,输入yes就OK
如果以上配置都成功了,那恭喜你,配置成功了
启动Hadoop
格式化hdfs文件系统
第一次启动时干的1
hdfs namenode -format
启动hdfs
1 | start-dfs.sh |
结果如下图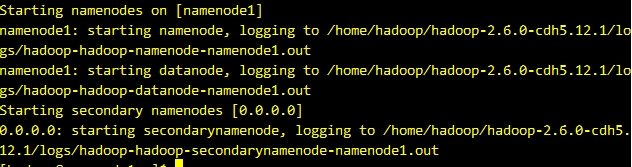
你可以使用jps命令查看当前运行的进程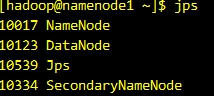
你也可以本地通过浏览器查看,打开浏览器输入 http://192.168.17.10:50070 【这个IP是前面配的固定IP地址】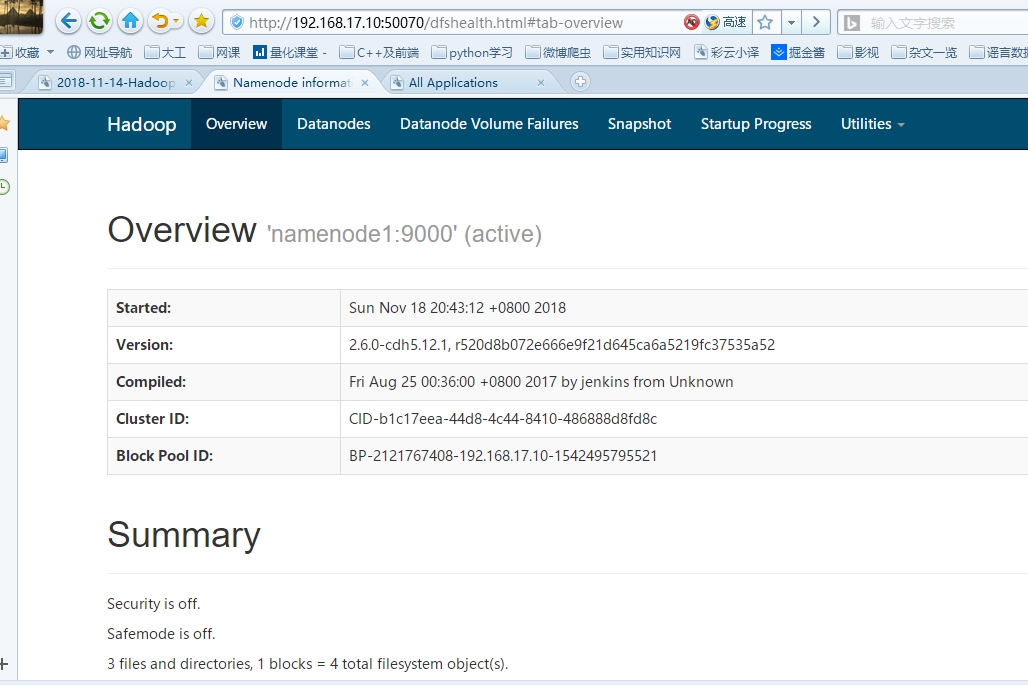
启动yarn
1 | start-yarn.sh |
master启动ResourceManager进程,slave启动NodeManager进程
你也可以本地通过浏览器查看,打开浏览器输入 http://192.168.17.10:8088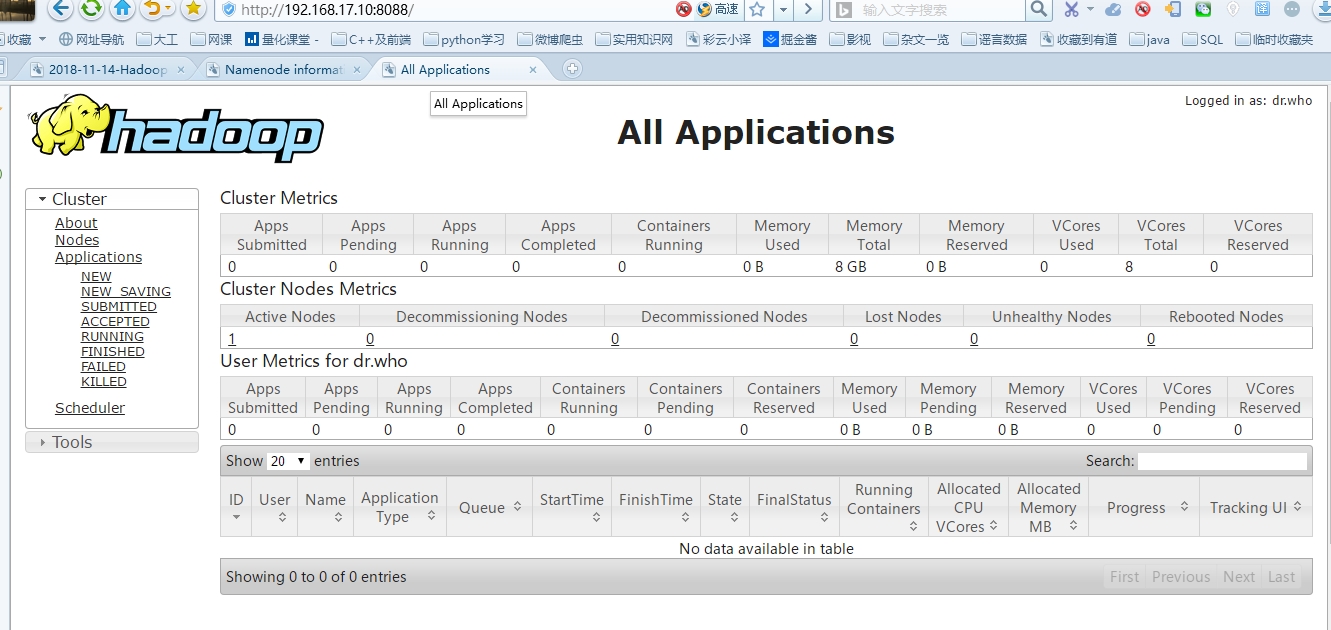
启动JobHistory Server(MR)
1 | mr-jobhistory-daemon.sh start historyserver |
记录分布式环境下提交的作业记录,namenode启动JobHistoryServer进程
你也可以本地通过浏览器查看,打开浏览器输入 http://192.168.17.10:19888
链接:文中所提的配置文件,提取码: ah7z

