初识MapReduce
先看一张图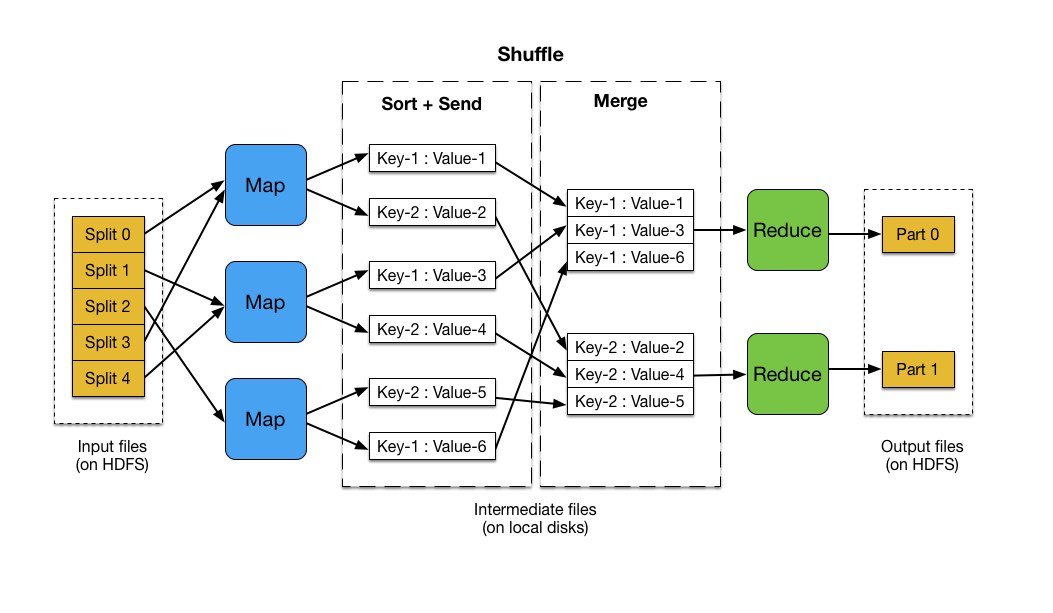
MapReduce程序词频统计源码分析
- 前言
- hdfs中有自己的数据类型,java中的Int对应IntWritable,String对应Text
- 为了实现文件序列化,编程中必须把Int、String转变为上面的两个
1 | public class WordCount { |
Windows下实现MapReduce编程初步
宿主机上开发环境配置
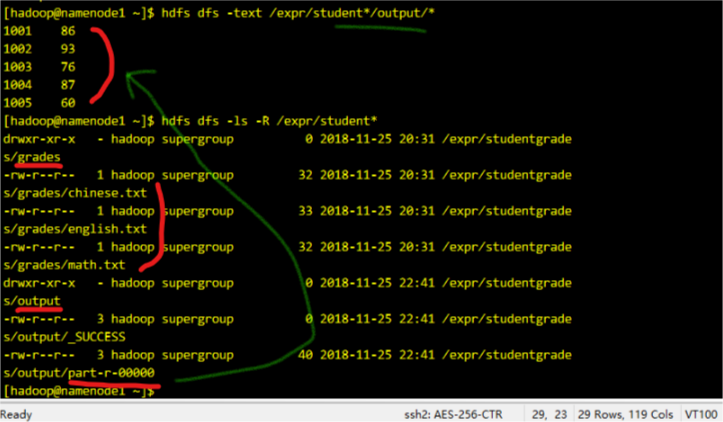
基于MapReduce统计学生平均成绩
如图,在hdfs的/expr/studentgrades/grades/ 下创建,几个文件,随便写几行数据,类似如下(学号 成绩):1
2
31001 90
1002 100
...
代码及注释如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132package gradesAverage;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import mapReduceTest.wordCount.WordCount;
import mapReduceTest.wordCount.WordCount.IntSumReducer;
import mapReduceTest.wordCount.WordCount.TokenizerMapper;
public class GradesAverage {
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private Text student = new Text();
private IntWritable grade = new IntWritable();
/* (non-Javadoc)
* @see org.apache.hadoop.mapreduce.Mapper#map(KEYIN, VALUEIN, org.apache.hadoop.mapreduce.Mapper.Context)
*/
/* (non-Javadoc)
* @see org.apache.hadoop.mapreduce.Mapper#map(KEYIN, VALUEIN, org.apache.hadoop.mapreduce.Mapper.Context)
*/
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
// StringTokenizer iTokenizer = new StringTokenizer(value.toString(),"\n");
System.out.println("key is:"+key+"value is: "+value.toString());
// while (iTokenizer.hasMoreTokens()) {
//
// }
String[] list_strs = value.toString().split(" ");
// 因为每行只有一个学号和对应成绩,不需要考虑切分多个词
student.set(list_strs[0]);
grade.set(Integer.parseInt(list_strs[1]));
context.write(student, grade);
// String line = value.toString(); //将输入的纯文本文件的数据转化成String
// System.out.println(line);//为了便于程序的调试,输出读入的内容
// //将输入的数据先按行进行分割
// StringTokenizer tokenizerArticle = new StringTokenizer(line,"\n");
// //分别对每一行进行处理
// while(tokenizerArticle.hasMoreTokens()){
// //每行按空格划分
// StringTokenizer tokenizerLine = new StringTokenizer(tokenizerArticle.nextToken());
// String strName = tokenizerLine.nextToken(); //学生姓名部分
// String strScore = tokenizerLine.nextToken();//成绩部分
// Text name = new Text(strName);//学生姓名
// int scoreInt = Integer.parseInt(strScore);//学生成绩score of student
// context.write(name, new IntWritable(scoreInt));//输出姓名和成绩
// }
}
}
public static class gradesAverageReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable gradesSum = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
int grades = 0;
for (IntWritable val : values) {
sum += 1;
grades += val.get();
}
System.out.println("student is:"+key.toString()+",grades is:"+grades+",sum is:"+sum);
gradesSum.set((int)grades/sum);
context.write(key, gradesSum);
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 1.设置HDFS配置信息
String namenode_ip = "192.168.17.10";
String hdfs = "hdfs://" + namenode_ip + ":9000";
Configuration conf = new Configuration(); // Hadoop配置类
conf.set("fs.defaultFS", hdfs);
conf.set("mapreduce.app-submission.cross-platform", "true"); // 集群交叉提交
/*
* conf.set("hadoop.job.user", "hadoop"); conf.set("mapreduce.framework.name",
* "yarn"); conf.set("mapreduce.jobtracker.address", namenode_ip + ":9001");
* conf.set("yarn.resourcemanager.hostname", namenode_ip);
* conf.set("yarn.resourcemanager.resource-tracker.address", namenode_ip +
* ":8031"); conf.set("yarn.resourcemtanager.address", namenode_ip + ":8032");
* conf.set("yarn.resourcemanager.admin.address", namenode_ip + ":8033");
* conf.set("yarn.resourcemanager.scheduler.address", namenode_ip + ":8034");
* conf.set("mapreduce.jobhistory.address", namenode_ip + ":10020");
*/
// 2.设置MapReduce作业配置信息
String jobName = "GradesAverage"; // 定义作业名称
Job job = Job.getInstance(conf, jobName);
job.setJarByClass(GradesAverage.class); // 指定作业类
job.setJar("export\\GradesAverage.jar"); // 指定本地jar包
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(gradesAverageReducer.class); // 指定Combiner类
job.setReducerClass(gradesAverageReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 3.设置作业输入和输出路径
String dataDir = "/expr/studentgrades/grades"; // 实验数据目录
String outputDir = "/expr/studentgrades/output"; // 实验输出目录
Path inPath = new Path(hdfs + dataDir);
Path outPath = new Path(hdfs + outputDir);
FileInputFormat.addInputPath(job, inPath);
FileOutputFormat.setOutputPath(job, outPath);
// 如果输出目录已存在则删除
FileSystem fs = FileSystem.get(conf);
if (fs.exists(outPath)) {
fs.delete(outPath, true);
}
// 4.运行作业
System.out.println("Job: " + jobName + " is running...");
if (job.waitForCompletion(true)) {
System.out.println("统计 success!");
System.exit(0);
} else {
System.out.println("统计 failed!");
System.exit(1);
}
}
}
运行结果如下:1
2
查看平均成绩结果文件,目录结构如图