Hadoop概述
Hadoop是分布式系统基础架构,其核心包括HDFS(分布式文件系统)、MapReduce(分布式计算系统)、YARN(分布式资源调度和管理系统)
Google三驾马车
- GFS发展成HDFS
- Google BigTable发展成HBase
- Google MapReduce发展成MapReduce
Hadoop生态系统
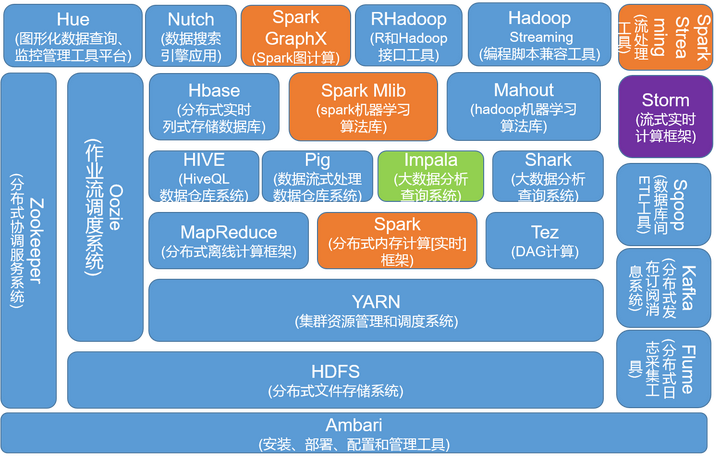
蓝色部分,是Hadoop生态系统组件,黄色部分是Spark生态组件。二者并非互斥,像MR和Spark是共生关系,Spark提供了基于内存的实时计算,Hadoop提供了Spark没有的分布式文件系统,但Spark不一定就依赖HDFS,可以借助AWS的S3
HSQL未来可能会被Spark SQL替代,现在很多企业都是HIVE SQL和Spark SQL两种工具共存,当Spark SQL逐步成熟的时候,就有可能替换HSQL;
MapReduce绝对会被Spark替换,趋势是这样,Spark发展很快
Hadoop中的算法库Mahout正被Spark中的算法库MLib所替代,我觉得可以在Spark学习中侧重选择Spark Mlib学习
但是Hadoop也非常重要,我感觉绝对不会被Spark取代。为什么呢?就是因为它的HDFS分布式文件系统
Hadoop先修准备Linux shell学习
掌握Hadoop集群搭建
见 大数据之Hadoop学习(环境配置)——Hadoop伪分布式集群搭建
有几点需要注意
- 安装配置JDK环境
编辑全局环境变量文件/etc/profile,最后要source /etc/profile生效
- 解压
.tar.gz文件
1 | # tar -zxvf hadoop-2.6.0-cdh5.12.1.tar.gz -C /home/hadoop |
- 解压
.tar文件
1 | # tar -xvf XXX.tar -C [解压到哪个目录] |
-C <目录>:这个选项用在解压缩,若要在特定目录解压缩,可以使用这个选项
-z或–gzip或–ungzip:通过gzip指令处理备份文件
-x或–extract或–get:从备份文件中还原文件
-v或–verbose:显示指令执行过程
-f<备份文件>或–file=<备份文件>:指定备份文件
- 在用户环境变量文件(
/home/hadoop/.bash_profile)中配置Hadoop相关环境变量
全局环境变量文件/etc/profile也可以,针对HADOOP_HOME, HADOOP_LOG_DIR, YARN_LOG_DIR, 追加PATH添加hadoop命令
- hadoop的九个配置文件
都在/hadoop-2.6.0-cdh5.12.1/etc/hadoop目录下
core-site.xml指明对外访问的uri
hdfs-site.xml指明元数据和实际数据放哪里,以及数据备份几份,还有是跳过身份验证
mapred-site.xml指明资源调度框架是yarn
yarn-site.xml指明yarn的aux-services和几个应用的地址
- 配置hadoop用户的免密登录
- 每台虚拟机上都创建秘钥,
$ ssh-keygen -t rsa,三次回车不加密码 - 将每个datanode节点上的公钥汇总到namenode1的
.ssh/authorized_keys文件中,$ ssh-copy-id -i ~/.ssh/id_rsa.pub namenode1 - 在namenode上将公钥加入授权文件
authorized_keys,并设置访问权限600,然后分发到每个datanode节点上$ scp authorized_keys datanode1:.ssh/
- 每台虚拟机上都创建秘钥,
HDFS理论基础和应用开发
hdfs文件系统特征
- 存储极大数目的信息(terabytes or petabytes),将数据保存到大量的节点当中。支持很大单个文件。
- 提供数据的高可靠性,单个或者多个节点不工作,对系统不会造成任何影响,数据仍然可用。
- 提供对这些信息的快速访问,并提供可扩展的方式。能够通过简单加入更多服务器的方式就能够服务更多的客户端。
- HDFS是针对MapReduce设计的,使得数据尽可能根据其本地局部性进行访问与计算。
掌握hadoop开发环境搭建
- Windows下,下次补充
- Linux系统下eclipse中配置hadoop开发环境
掌握hdfs常用基本命令
hdfs基本命令类似Linux命令格式,有三种1
2
3hadoop fs -cmd
hadoop dfs -cmd
hdfs dfs -cmd (推荐)
基本命令必须掌握的有1
2
3
4
5
6
7-ls [-R]
-mkdir [-p]
-put [-f] 本地目录 目标目录
-get 文件路径 本地路径
-cat
-text
-rm [-r]
hdfs管理命令hdfs dfsadmin -cmd1
2
3-printTopology
-report
-safemode [get|enter|leave]
最后这个挺重要的,get是查看当前状态(是否进入安全状态),enter是进入安全状态,leave是离开
- 更多内容可以参考操作hdfs
- hadoop中文文档命令手册
掌握hdfs API开发
了解分布式资源管理及调度框架YARN的优势何在
因为Hadoop1.0版本中是使用的MapReduce作为资源管理和调度平台的,后来在2.0中就被取代了,但MR这种编程模式仍被保留了
MapReduce编程前的准备
- 了解hdfs压缩与解压缩概念
- 了解hdfs如何序列
对数据压缩可以优化磁盘使用率,能够提高数据在磁盘和网络中的传输速度
序列化是指将结构化对象转化为字节流以便在网络上进程间传输或写到磁盘上进行永久存储的过程,相反还有反序列化。hadoop对数据序列化好处不仅是这两点,像格式更加紧凑,易于管理都是
以上说的这些序列化,只要知道就可以了,hadoop通过Writable接口对它们进行了封装,如下
Java基本类型在hadoop上进行Writable封装,如图: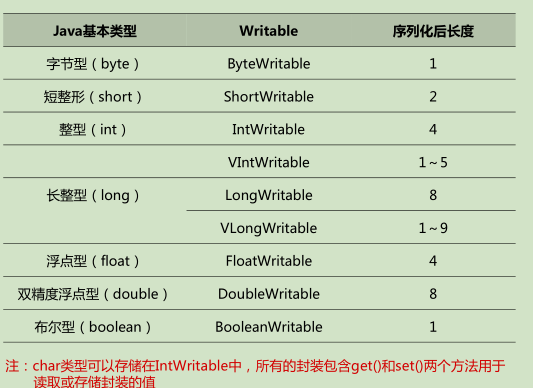
常用的无非就是IntWritable、LongWritable、FloatWritable,图中V开头的是定长与不定长的区分,我没用过
其次是Text、NullWritable类
Text是针对utf-8序列的Writable类,可认为是java中的String
NullWritable是hadoop中的空类型,可认为是null,多用来占位使用
而hadoop有提供get和set方法,在java类型和可序列化类型间转换,如
1 | IntWritabel one = new IntWritable(); |
自定义Writable类以及WritableComparable类
前者是可序列化类,必须实现接口的方法有:1
2Writable.write(DataOutput out)
Writable.readFields(DataInput in)
后者是可序列化且可比较类,必须实现接口的方法有:1
2
3Writable.write(DataOutput out)
Writable.readFields(DataInput in)
Comparable.compareTo(T o)
从wordcount词频统计入手MapReduce编程
MapReduce编程的核心就是一句话“分而治之,迭代汇总”,只要是分治法可以解决的问题,它都可以做
下面给出wordcount源码,源码来自hadoop自带的词频统计的jar包,稍微改动。如下代码有注释。MapReduce编程都是这么一个模块式编程流程,看懂这个其他模式都一通百通1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83public class WordCount2 {
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context ) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
//1.设置HDFS配置信息
String namenode_ip = "192.168.17.10"; //这个是你集群中设置的ip
String hdfs = "hdfs://" + namenode_ip + ":9000";
Configuration conf = new Configuration(); //Hadoop配置类
conf.set("fs.defaultFS", hdfs);
conf.set("mapreduce.app-submission.cross-platform", "true"); //跨平台提交
//集群交叉提交
/* conf.set("hadoop.job.user", "hadoop");
conf.set("mapreduce.framework.name", "yarn");
conf.set("mapreduce.jobtracker.address", namenode_ip + ":9001");
conf.set("yarn.resourcemanager.hostname", namenode_ip);
conf.set("yarn.resourcemanager.resource-tracker.address", namenode_ip + ":8031");
conf.set("yarn.resourcemtanager.address", namenode_ip + ":8032");
conf.set("yarn.resourcemanager.admin.address", namenode_ip + ":8033");
conf.set("yarn.resourcemanager.scheduler.address", namenode_ip + ":8034");
conf.set("mapreduce.jobhistory.address", namenode_ip + ":10020"); */
//2.设置MapReduce作业配置信息
String jobName = "WordCount2"; //定义作业名称
Job job = Job.getInstance(conf, jobName);
job.setJarByClass(WordCount2.class); //指定作业类
job.setJar("export\\WordCount2.jar"); //指定本地jar包
job.setMapperClass(TokenizerMapper.class); //指定Mapper类
job.setCombinerClass(IntSumReducer.class); //指定Combiner类
job.setReducerClass(IntSumReducer.class); //指定Reducer类
job.setOutputKeyClass(Text.class); //指定输出Key的类型
job.setOutputValueClass(IntWritable.class); //指定输出Value类型
//3.设置作业输入和输出路径
String dataDir = "/expr/wordcount/data"; //实验数据目录
String outputDir = "/expr/wordcount/output"; //实验输出目录
Path inPath = new Path(hdfs + dataDir);
Path outPath = new Path(hdfs + outputDir);
FileInputFormat.addInputPath(job, inPath); //文件输入目录
FileOutputFormat.setOutputPath(job, outPath); //文件输出目录
//如果输出目录已存在则删除
//必须删,hadoop的一个bug,不删会报错
FileSystem fs = FileSystem.get(conf);
if(fs.exists(outPath)) {
fs.delete(outPath, true);
}
//4.运行作业
System.out.println("Job: " + jobName + " is running...");
if(job.waitForCompletion(true)) {
System.out.println("success!");
System.exit(0);
} else {
System.out.println("failed!");
System.exit(1);
}
}
}
- 点击这里下载运行:wordCount源码文件
- 启动hdfs、yarn【
start-dfs.sh、start-yarn.sh,或者start-all.sh】 - 可启动jobhistory服务
mr-jobhistory-daemon.sh start historyserver - 确保hdfs上
/expr/wordcount/data目录下有数据,没有的话hdfs dfs -put xxx /expr/wordcount/data上传即可 - eclipse下运行即可(hadoop插件会自动上传所需的编译文件以便运行),或者上传打好的jar包到linux上,通过
hadoop jar来运行 - 查看运行结果
hdfs dfs -cat /expr/wordcount/output/part-r-00000(通过hadoop插件也可以看到)
MapReduce程序运行在一个分布式集群中,合理利用集群中的资源,发挥出分布式集群中各个节点本身的处理能力。MapReduce框架使分布式计算中网络处理、协调不同节点的资源调配、任务协同变得简单透明
MapReduce分为Map和Reduce两个阶段,是在HDFS存储数据的基础上,将一个较大的计算任务分解成若干个小任务,每个小任务都由一个Map程序来计算(尽量在数据所在的节点上完成),再将每个Map的计算结果由一个或多个Reduce程序合并计算得到最终结果
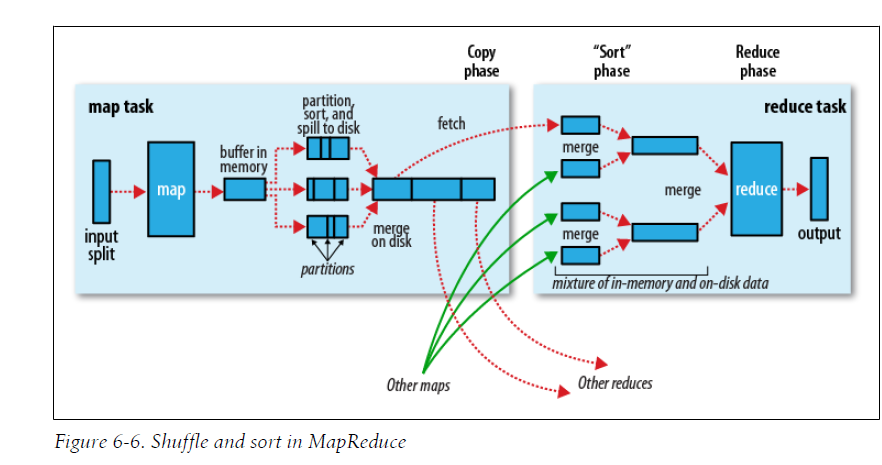
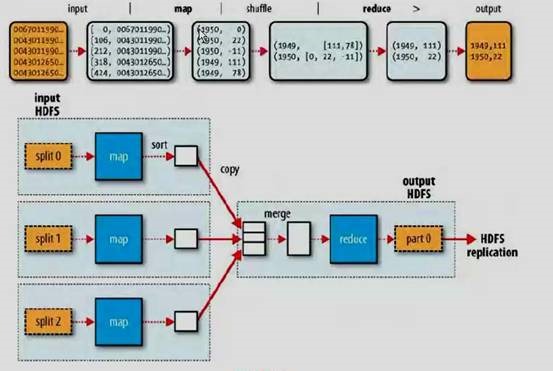
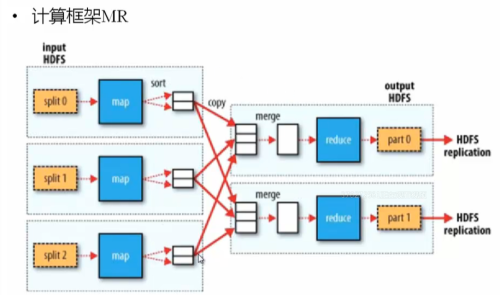
MapReduce过程详解【含Shuffle过程】
这一步是为了充分认识了解MR的整个过程,能够更好地了解该如何设计MR程序以解决问题
Mapper类源码阅读
1 | protected void setup(Context context) throws IOException, InterruptedException { |
Reducer类源码阅读
1 | /** |
这部分内容太多了,不在这里写了,可以看我这几篇博客【MapReduce详解及源码解析(一)】——分片输入、Mapper及Map端Shuffle过程,MapReduce:详解Shuffle过程
终极杀招 MapReduce系统编程实战操练
大数据之Hadoop学习——动手实战学习MapReduce编程实例
目录如下1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31- MapReduce编程实例
- 1.自定义对象序列化
- 2.数据去重
- 3.数据排序、二次排序
- 4.自定义分区
- 5.计算出每组订单中金额最大的记录
- 多文件输入输出、及不同输入输出格式化类型
- 6.合并多个小文件
- 7.分组输出到多个文件
- 8.join操作
- 9.计算出用户间的共同好友
- MapReduce理论基础
- Hadoop、Spark学习路线及资源收纳
- MapReduce实战系统学习流程
- 词频统计
- 数据去重
- 数据排序
- 求平均值、中位数、标准差、最大/小值、计数
- 分组、分区
- 数据输入输出格式化
- 多文件输入、输出
- 多文件输入、输出
- 单表关联
- 多表关联
- 倒排索引
- TopN
- 作业链
- 项目
- Web日志KPI指标分析
- PeopleRank算法实现
- 推荐系统——基于物品的协同过滤算法实现
hadoop资源分享
1 | 一、学习路线图 |

